Spechler and Cannarella's paper predicting the death of Facebook has been taking a lot of flak. While I do think there are some issues applying their model to Facebook and MySpace, they're not the ones that most people are citing.
The most common complaint about the Princeton Facebook paper that I've seen is that Facebook is not a disease. Facebook may not be a disease, but that doesn't mean a model that describes how diseases spread isn't a good model for how Facebook spreads. Models based on the disease spread analogy have been used for decades in marketing. The famous "Bass Model" is just a relabeled disease model. Frank Bass's original paper has been cited thousands of times and was named one of the ten most influential papers in Management Science. While it's received its fair share of criticism, the entirety of The Tipping Point is based on the disease spread analogy. Gladwell even writes, "... ideas and behavior and messages and products sometimes behave just like outbreaks of infectious disease."
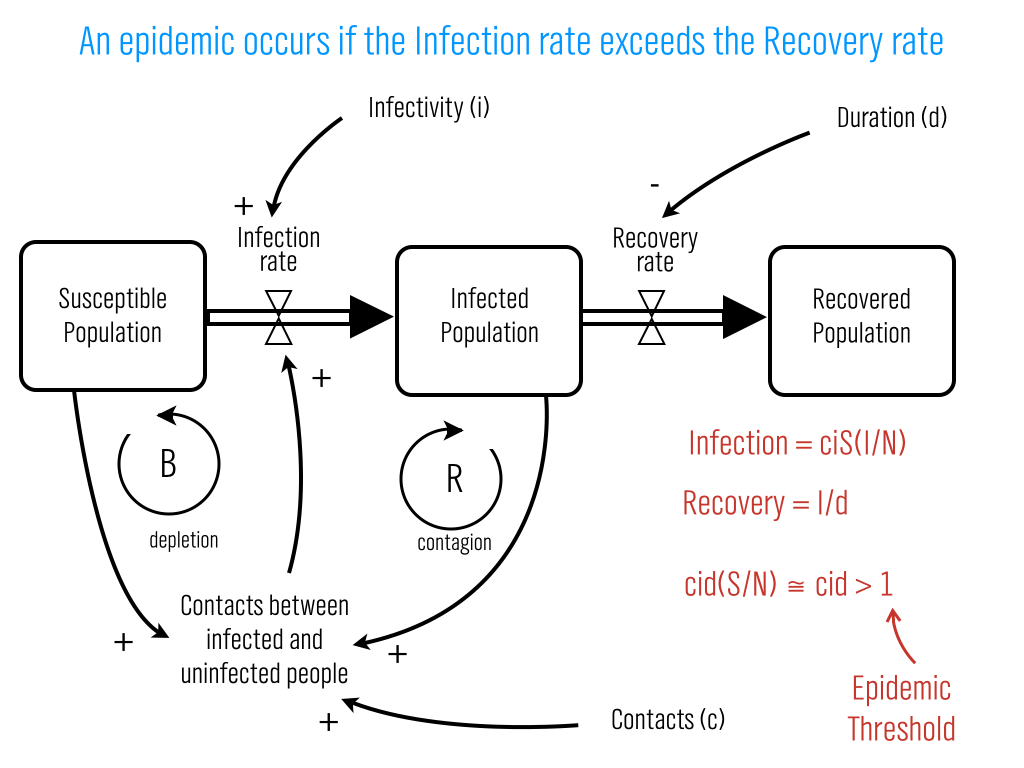
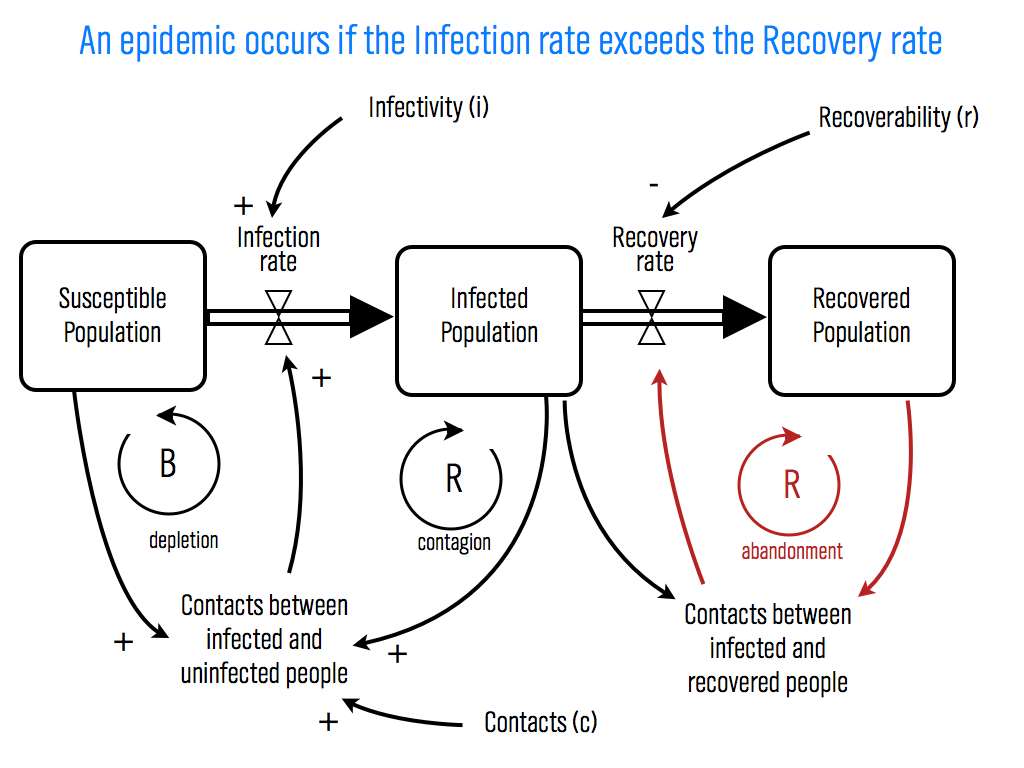
Interestingly, one of the major points of Spechler and Cannarela's paper is that online social networks do NOT spread just like a disease, that's why they had to modify the original SIR disease model in the first place. (See an explanation here.)
But, the critics have missed this point and are fixated on particulars of the disease analogy. For example, Lance Ulanoff at Mashable (who has one of the more evenhanded critiques) says, "How can you recover from a disease you never had?" He's referring to the fact that in Spechler and Cannarella's model, some people start off in the Recovered population before they've ever been infected. These are people who have never used Facebook and never will. It is a bit confusing that they're referred to as "recovered" in the paper, but if we just called them "people not using Facebook that never will in the future" that would solve the issue. Ulanoff has the same sort of quibble with the term recovery writing, "The impulse to leave a social network probably does spread like a virus. But I wouldn’t call it “recovery.” It's leaving that's the infection." Ok, fine, call it leaving, that doesn't change the model's predictions. Confusing terminology doesn't mean the model is wrong.
All of this brings up another interesting point, how could we test if the model is right? First off, this is a flawed question. To quote the statistician George E. P. Box, "... all models are wrong, but some are useful." Models, by definition, are simplified representations of the real world. In the process of simplification we leave things out that matter, but we try to make sure that we leave the most important stuff in, so that the model is still useful. Maps are a good analogy. Maps are simplified representations of geography. No map completely reproduces the land it represents, and different maps focus on different features. Topographic maps show elevation changes and road maps show highways. One kind is good for hiking the Appalachian trail, another is good for navigating from New York City to Boston. Models are the same — they leave out some details and focus on others so that we can have a useful understanding of the phenomenon in question. The SIR model, and Spechler and Cannarela's extension leave out all sorts of details of disease spread and the spread of social networks, but that doesn't mean they're not useful or they can't make accurate predictions.
Spechler and Cannarela fit their model to data on MySpace users (more specifically, Google searches for MySpace), and the model fits pretty well. But this is a low bar to pass. It just means that by changing the model parameters, we can make the adoption curve in the model match the same shape as the adoption curve in the data. Since both go up and then down, and there are enough model parameters so that we can change the speed of the up and down fairly precisely, it's not surprising that there are parameter values for which the two curves match pretty well.
There are two better ways that the model could be tested. The first method is easier, but it only tests the predictive power of the model, not how well it actually matches reality. For this test, Spechler and Cannarela could fit the model to data from the first few years of MySpace data, say from 2004 to 2007, and see how well it predicts MySpace's future decline.
The second test is a higher bar to clear, but provides real validation of the model. The model has several parameters — most importantly there is an "infectivity" parameter (β in the paper) and a recovery parameter (γ). These parameters could be estimated directly by estimating how often people contact each other with messages about these social networks and how likely it is for any given message to result in someone either adopting or disadopting use of the network. For diseases, this is what epidemiologists do. They measure how infectious a disease is and how long ti takes for someone to recover, on average. Put these two parameters together with how often people come into contact (where the definition of "contact" depends on the disease — what counts as a contact for the flu is different from HIV, for example), and you can predict how quickly a disease is likely to spread or die out. (Kate Winslet explains it all in this clip from Contagion.) So, you could estimate these parameters for Facebook and MySpace at the individual level, and then plug those parameters into the model and see if the resulting curves match the real aggregate adoption curves.
Collecting data on the individual model parameters is tough. Even for diseases, which are much simpler than social contagions, it takes lab experiments and lots of observation to estimate these parameters. But even if we knew the parameters, chances are the model wouldn't fit very well. There are a lot of things left out of this model (most notably in my opinion, competition from rival networks.)
Spechler and Cannarella's model is wrong, but not for the reasons most critics are giving. Is it useful? I think so, but not for predicting when Facebook will disappear. Instead it might better capture the end of the latest fashion trend or Justin Bieber fever.