Last week the website of The Atlantic had a nice network visualization of the top tweets linking to articles on gun politics. You should go check out their site where the network visualization is interactive, but here is a static picture so you get the idea. 
Each node in this network is one of the top 100 most tweeted weblinks on gun politics during the week from Sunday 2/17 to Sunday 2/24. The creator of the network visualization collected all of the tweets that mentioned terms like "gun rights," "gun control," "gun laws," etc. and then looked for the most popular links in those tweets. (One thing I wonder about is how they dealt with shortened URLs. Since tweets are limited to 140 characters or less, when most people post a link on Twitter they shorten the URL using a service like bit.ly. This means that two people that are ultimately linking to the same article might post different URLs. Many news services have a built in "Tweet this" button, which may give the same shortened URL to everyone who clicks it, so those articles would get many consistent links, where articles or posts without a "Tweet this" button might have many links pointing to them, but all with different URLs coming from each time a person shortened the link individually. All of this is just a technical aside though, because I am a 100% sure the main point of the network visualization, which I haven't even gotten to yet, would still show up.)
The edges in the network visualization connect two pages if the same Twitter account posted links to both pages. The point is that we see two very distinct clusters with lots of edges within the clusters and not too many between them. Of course, taking a loser look at the network visualization we see that one of the groups consists of pro gun control articles and the other contains anti gun control pages. The network science term for this phenomenon is homophily i.e. nodes are more likely to connect to other nodes that are similar to them. Homophily shows up in lots and lots of networks. Political network visualizations almost always exhibit extreme homophily. For example, take a look at this network of political blogs created by Lada Adamic and Natalie Glance (they have generously made the data available here).
 In this network the nodes are blogs about politics and two blogs are connected if there is a hyperlink from one blog to another. Blue blogs are liberal blogs and red blogs are conservative.
In this network the nodes are blogs about politics and two blogs are connected if there is a hyperlink from one blog to another. Blue blogs are liberal blogs and red blogs are conservative.
Or, take a look at this network of senators created by a group in the Human-computer Interaction Lab at the University of Maryland.
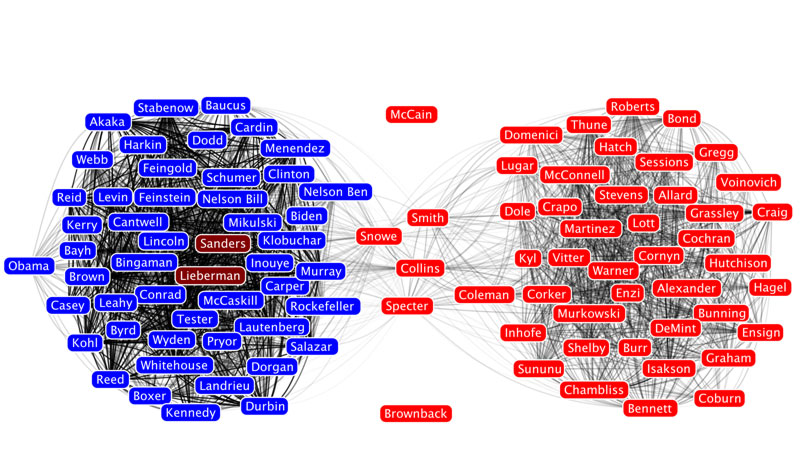
Here, the nodes are senators and two senators are connected if they voted the same way on a threshold number of roll call votes.
Homophily shows up in other types of social networks as well, not only political networks. For example, take a look at this network of high school friendships from James Moody's paper "Race, school integration, and friendship segregation in America," American Journal of Sociology 107, 679-716 (2001).
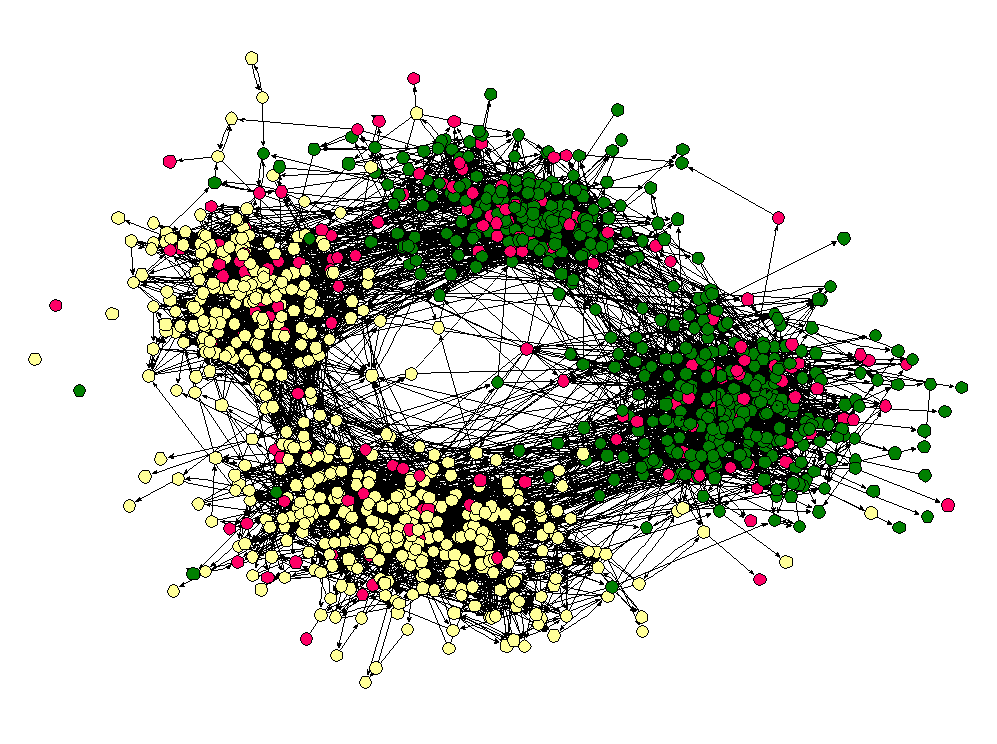
Here the nodes are students in a high school and two nodes are connected if one student named the other student as friend (the data was collected as part of the Add Health study). The color of the nodes corresponds to the race of the students. As we can see, "yellow" students are much more likely to be friends with other yellow students and "green" students are more likely to connect to other green students. (Interestingly, the "pink" students, who are in the vast minority seem to be distributed throughout the network. I once heard Matt Jackson say that this is the norm in many high schools — if there are two large groups and one small one, the members of the small group end up identifying with one or the other of the two large groups.)
Homophily is actually a more subtle concept than it appears at first. The thorny issue, as is often the case, is causality. Why do similar nodes tend to be connected to one another? The problem is so deeply ingrained in the concept of homophily that it sometimes leads to ambiguity in the use of the term itself. Some people use the word homophily to refer to the observation that nodes in a network are more likely to connect to similar nodes in the network than we would expect due to chance. In this case, there is no mention of the underlying reason why similar nodes are connected to one another, just that they are. When other people use the term homophily, they mean the tendency for nodes in a network to select similar nodes in the network to form connections with. To keep the distinction clear, some people even refer to the former definition as observed homophily.
To understand the difference it helps to think about other reasons why we might see similar nodes preferentially connected to one another. The casual stories fall into three basic categories: influence, network dynamics, and exogenous covariates. For many people, the influence story is the most interesting. In this explanation, we imagine that the network of connections already exists, and then nodes that are connected to one another affect each other's characteristics so that network neighbors end up being similar to one another. For example, in a series of papers looking at a network of friends, relatives, and geographic neighbors from the Framingham Heart study, Christakis and Fowler argue that network neighbors influence one another's weight, tendency to smoke, likelihood to divorce, and depression. While not everyone is convinced by Christakis and Fowler's evidence for a contagion effect, we can all agree that in their data obese people are more likely to be connected to other obese people, smokers tend to be friends with smokers, people that divorce are more likely to be connected to others that divorce, and depressed folks are more likely to be connected to other depressed people than we would expect due to chance.
In the network dynamics story, nodes form or break ties in a way that shows a preference for a particular attribute. Our intuition is that liberal blogs like to link to other liberal blogs more than they like to link to conservative blogs. This is what some people take as the definition of homophily. Since the word literally means "love of the same" this makes some sense.
But, just because we see observed homophily doesn't mean people are preferentially linking to other people that are like them. This is reassuring when we see homophily on dimensions like race as in the high school friendship network above. Clearly, the students are not influencing the race of their friends, but this doesn't mean the fact that we observe racial homophily doesn't imply the students are racist — there could be what we call an exogenous covariate that is leading to the observation of homophily. For example, it could be that these students leave in a racially segregated city and students are more likely to be friends with other students that live close to them. In this case, students prefer to be friends with other students that live near them, and living near one another just happens to increase the likelihood that the students share the same race. One particularly tricky covariate is having a friend in common. Another common observation in social networks is what is called triadic closure. In lay terms, triadic closure means that two people with a friend in common are likely to be friends with each other — the triangle closes instead of remaining an open like a V. It could be that, in the high school friendship network, there is a sight tendency for some students to choose others of their same race as friends; either because of another variable like location or because of an actual racial bias, but the appearance of racial homophily could be significantly amplified by triadic closure. If one student chooses two friends that are of the same race, triadic closure is likely to result in third same race tie. It turns out that, at least in some cases where scholars have been able to untangle these various stories, triadic closure and homophily on other covariates explains a lot of observed racial homophily (see e.g. Wimmer and Lewis or Kossinets and Watts).
So, what about the gun control network? In this case, we can rule out influence, since the articles had to already exist and have a stance on gun control before someone can tweet a link to them. That is, the "state" of the node as pro or anti gun control precedes the formation of a tie connecting them in the Atlantic's network. But as far as the other explanations go, it's probably a mix. An obvious exogenous covariate is source. If I read news on the website of MSNBC and you go to the Fox website, I'm more likely to tweet links to pro gun control articles and your more likely to to tweet anti gun control links, even if we are both just tweeting links to every gun control article we read. Undoubtedly though, many people are using Twitter as a way to spread information that supports their own political opinions, so someone that is pro gun control will tweet pro gun control links and vice versa. This however doesn't mean that gun control advocates aren't reading 2nd amendment arguments and gun rights supporters aren't reading what the gun control folks have to say — it just means that they aren't broadcasting it to the rest of the world when they do.